TiDB 简单介绍(部分感兴趣点)
Contents
TiDB 是一款定位于在线事务处理/在线分析处理( HTAP: HybridTransactional/Analytical Processing)的融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时OLAP 等重要特性。同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低。
整体架构
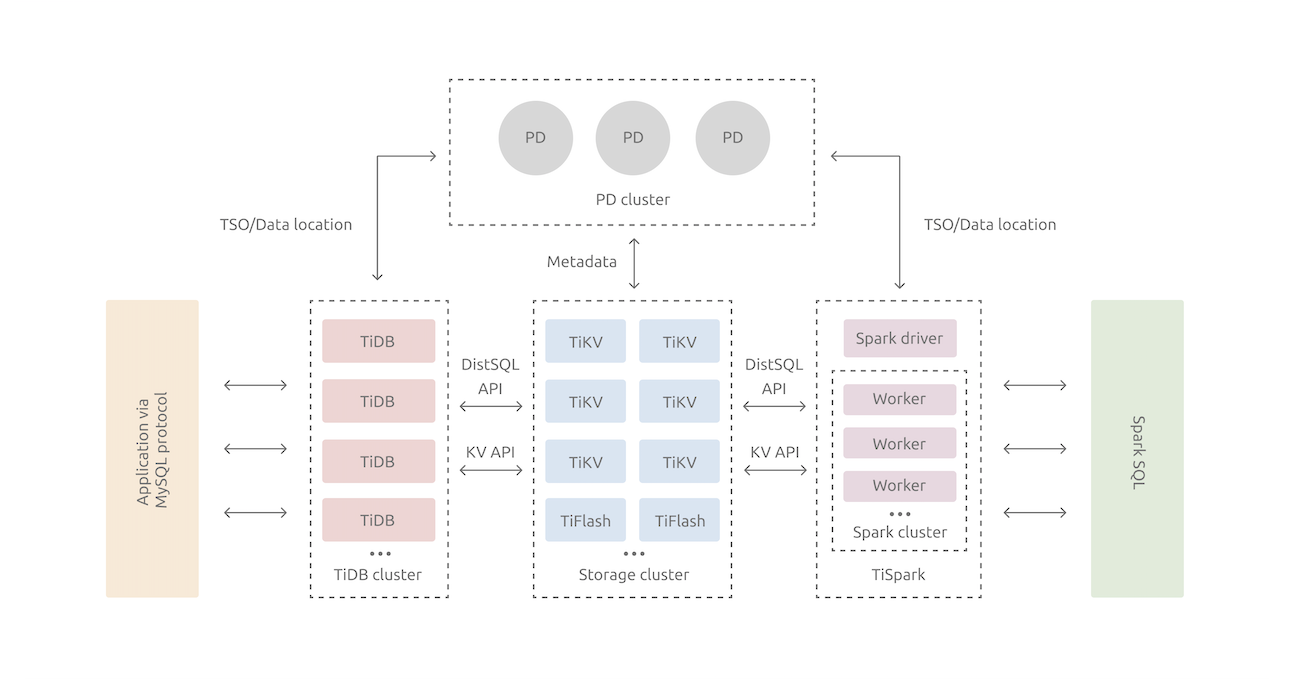
TiDBServer层
用户接口层,兼容MySQL协议,负责SQL解析、优化和生成执行计划。本身无状态,不存储实际数据,只负责处理SQL和转发数据读取请求,可多实例部署,用于负载均衡。PD Server层
TiDB 集群的元信息管理模块,负责存储每个 TiKV节点实时的数据分布情况和集群的整体拓扑结构、为事务分配ID、同时根据TiKV节点状态进行数据调度。PD节点至少三节点部署,利用Raft分布式协议保证高可用性。存储节点:
- TiKVServer层:分布式Key-Value存储引擎,负责存储数据。每个TiKV实例可以存储多个Region,每个Region为一个数据范围(Key)分片。默认提供SI(快照隔离)级别,这是TiDB在SQL层面支持分布式事务的核心。TiKV同样使用Raft分布式协议,默认3副本,保证高可用性。
- TiFlash 层:TiFlash 是一类特殊的存储节点。和普通 TiKV
节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
数据存储
数据模型
TiDB 的数据存储在 TiKV 层,TiKV 的数据存储模型使用的是 Key-Value模型,所有的数据都被组织成KV的形式。对于一个 Table来说,需要存储的数据包括三部分:表的元信息、表中的行数据和索引数据。TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID。每行数据按照如下规则进行编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_recordPrefixSep{rowID} |
对于 Index 数据,会按照如下规则编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue |
Index 数据还需要分为是 Unique Index 和 非Unique Index,对于 Unique Index 不能按照上述方式进行编码:
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID |
上述方式保证同一个 indexedColumnsValue 只会出现在一个行中,实现 Unique Index。
数据本地存储
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB中,具体的数据落地由 RocksDB负责。(注:TiDB官方解释是单独开发一个单机高性能的存储引擎工作量很大,而 RocksDB 由 Facebook 开发, 可以满足 TiKV的存储需求)
数据分片
TiKV 可以看做是一个巨大的有序的 KVMap,那么为了实现存储的水平扩展,数据将被分散在多台机器上。KV系统通常有两种分片方式:
- Hash:按照 Key 做 Hash,根据 Hash 值选择对应的存储节点。
- Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上。
TiKV 选择 Range 的方式分片,将整个 Key-Value
空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个
Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在
TiKV 中默认是 96MB。
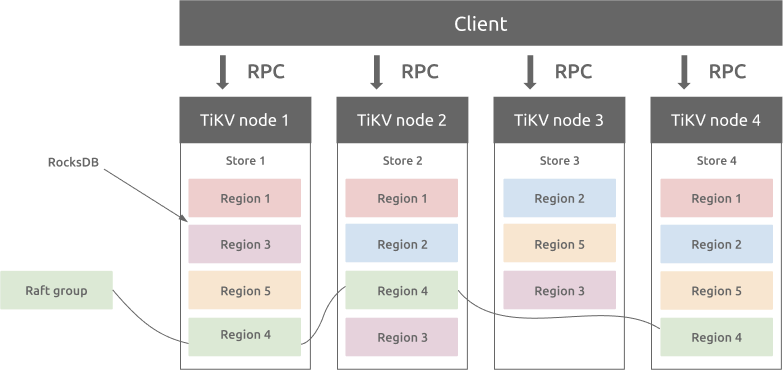
TiKV通过 Range 分片的方式,可以使得Key连续的数据位置比较相近;同时 PD节点可以通过调整 Region 的存储位置,使得数据分布均匀,从而实现负载均衡;一个 Region 有多个副本,多个副本构成一个 RaftGroup,默认情况下,所有的读和写都是通过 Leader 进行,读操作在 Leader 上即可完成,而写操作再由 Leader 复制给 Follower
并发控制
TiDB对于数据的并发控制和大多数数据库一样采用MVCC(多版本并发控制)。TiKV 中 MVCC 实现是通过在 Key 后面添加版本号来实现的:
1 | Key1_Version3 -> Value |
注释:RocksDB 底层存储的时候也会加入数据版本信息,TiKV在每个Key上也加入来版本信息,实际的话每个 Key 应该存在两个版本信息,用途是不一样的
在 TiKV 中 提供了以下的 MVCC 访问数据的接口:
- MVCCGet(key, version), 返回某 key 小于等于 version 的最大版本的值
- MVCCScan(startKey, endKey, limit, version), 返回 [startKey, endKey)
区间内的 key 小于等于 version 的最大版本的键和值,上限 limit 个 - MVCCPut(key, value, version) 插入某个键值对,如果 version
已经存在,则覆盖它。上层事务系统有责任维护自增version来避免 read-modify-write。 - MVCCDelete(key, version) 删除某个特定版本的键值对,这个需要与上层的事务删除接口区分,只有 GC 模块可以调用这个接口
MVCC 在整个TiKV的架构中的位置如下图:
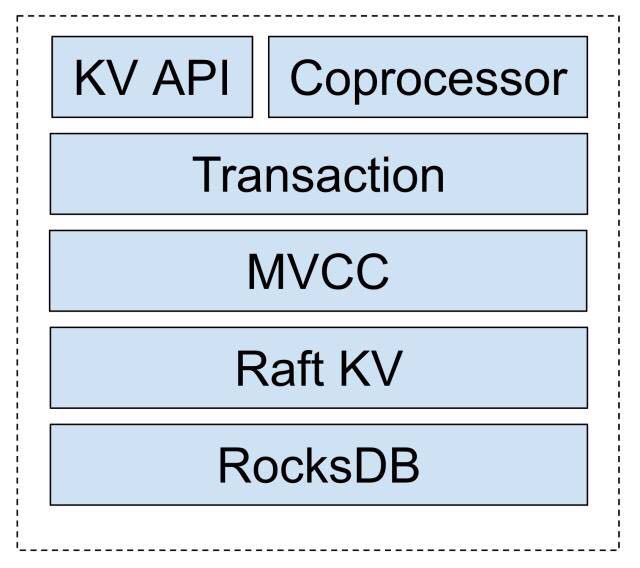
可以看出MVCC是TiKV实现分布式事务的基础。同时为了防止无效版本数据带来的存储开销,TiKV
有垃圾回收机制,如果该数据只存在一个版本那么就保留,如果存在多个版本,并且在 safe point 后存在 Put 或 Delete 记录,那么比这条记录旧的记录是可以被删除的。
TiDB事务
事务隔离级别
ANSI 根据允许出现的异常,定义了 4 种隔离级别:读未提交 (READ UNCOMMITTED)、读已提交 (READ COMMITTED)、可重复读 (REPEATABLE READ)、串行化 (SERIALIZABLE)。TiDB 实现了快照隔离 (Snapshot Isolation,SI) 级别的一致性(为了和MySQL 保持一致,又称为 "可重复读")。该隔离级别不会出现狭义上的幻读(A3),但不会阻止广义上的幻读 (P3),同时,SI 还会出现写偏斜,而 ANSI 可重复读隔离级别不会出现写偏斜,会出现幻读。至于为什么会出现这个情况可以参考 A Critique of ANSI SQL Isolation Levels和 Write-Skew。
从 TiDB v4.0.0-beta 版本开始,TiDB 支持使用 Read Committed 隔离级别。
TiDB 乐观事务实现
TiDB 基于 Google Percolator实现了支持完整 ACID、基于快照隔离级别(Snapshot Isolation)的分布式乐观事务。TiDB 乐观事务需要将事务的所有修改都保存在内存中,直到提交时才会写入 TiKV 并检测冲突。
快照隔离实现
Percolator 使用多版本并发控制(MVCC)来实现快照隔离级别,TiDB 使用 PD 作为全局授时服务(TSO)来提供单调递增的版本号
- 事务开始时获取 Start timestamp,也是快照的版本号;事务提交时获取 Commit timestamp,同时也是数据的版本号
- 事务只能读到在事务 Start timestamp 之前最新已提交的数据
- 事务在提交时会根据 Timestapm 判断数据冲突,如果在事务执行期间[Start,Commit] 有其他事务写了同样的数据,则回退事务。
事务原子性实现 (2PC)
TiDB 使用两阶段提交(Two-Phase Commit)来保证分布式事务的原子性,分为
Prewrite 和 Commit 两个阶段:
- Prewrite:对事务修改的数据检测冲突,无冲突则加锁,并选择其中一个为
Primary Key(以此Primay Key的提交成功与否作为事务的提交成功标志)。 - Commit:Prewrite 全部成功后,先同步提交
Primary Key,成功后事务提交成功,其他Secondary Keys会异步提交。
TiDB 悲观事务实现
乐观事务模型在一定程度上可以提升系统的并发性,特别是当数据冲突比较少的时候在分布式系统中有极大的性能优势。但是在某些场景下,如果事务冲突的概率比较大,会导致事务一直失败并重试(饥饿)。所以为了解决此类问题,TiDB 实现了悲观事务模型。
基于 Percolator 的悲观事务
悲观事务在 Percolator 乐观事务基础上实现,在 Prewrite 之前增加了 Acquire
Pessimistic Lock 阶段用于避免 Prewrite 时发生冲突:
- 每个 DML 都会加悲观锁,锁写到 TiKV 里,同样会通过 raft 同步。
- 悲观事务在加悲观锁时检查各种约束,如
Write Conflict key唯一性约束等。 - 悲观锁不包含数据,只有锁,只用于防止其他事务修改相同的
Key,不会阻塞读,但 Prewrite 后会阻塞读(和 Percolator 相同,但有了大事务支持后将不会阻塞读)。 - 提交时同 Percolator,悲观锁的存在保证了 Prewrite 不会发生
Write Conflict,保证了提交一定成功。
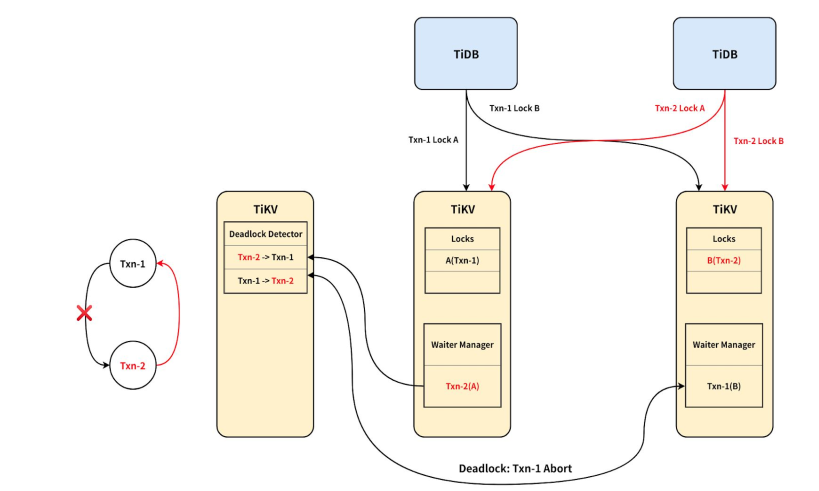
分布式死锁检测
在悲观事务过程中,可能发生死锁,并且死锁可能存在多个节点上,TiDB 使用分布式死锁检测机制。当一个事务需要等锁时,会向死锁检测器 Leader(同样是一个Raft集群)发起等锁请求,Leader 会汇总各个事务的等锁情况,如果发现有死锁情况,会让产生死锁的某个事务 abort,解除死锁。
TiDB故障恢复
TiKV 集群数据恢复
TiDB 中数据都存储在 TiKV 中,部分元数据存在 PD 中,而他们都是基于Raft
协议的多副本架构,所以在少副本宕机的情况下(少于一半),数据依旧不会丢失,此时只需要重新恢复节点或者加入新的节点即可。对于多个副本宕机的情况,可能存在数据无法找回的情况。
对于一个 3 副本的 TiKV 集群,出现 宕机的情况的时候。
故障 Region 处理,针对 Region 数据丢失的严重情况,可分为两种:
- Region 至少还有 1 个副本,恢复思路是在 Region 的剩余副本上移除掉所有位于故障节点上的 Peer,这样可以用这些剩余副本来重新选举和补充副本来恢复。
- Region 的所有副本都丢失了,这个 Region 的数据就丢失了,无法恢复。 可以通过创建 1 个空 Region 来解决 Region 不可用的问题
丢失数据处理
- 根据故障 Region ID 找到对应的表,找到相关用户并询问用户在故障前的某一段时间内的具体操作,重放日志即可。
- 如果可以重导,则是最简单的处理方式。否则的话,则只能对重要的数据表,检查数据索引的一致性,保证还在的数据是正确无误的。
TiDB事务恢复
事务一般是一组数据操作的序列,执行过程需要保证其原子性,如果在事务执行过程中遇到宕机等情况,需要正确的恢复数据。在 MySQL 中,主要是利用 redo log 和 undo log 来保证,redo log 记录了事务执行过程中对数据的修改的过程,undo log 简单来说就是操作的一个逆过程,当数据库宕机后,可以从持久化的 redo log 恢复出宕机前的未落盘的脏页数据,并且还可以根据 undo log 日志回滚未提交的日志,保证事务的原子性。
但是 TiDB 和 MySQL 整体不同的地方在于,TiDB 是存储计算分离的架构,TiDB-server 层是一个无状态的服务层,不记录数据,并且在底层存储 MySQL 使用的是 B+Tree,采取本地更新机制,而 TiKV 则是基于 MVCC 的异地更新机制的(LSM)的 RocksDB。所以在事务恢复过程中与 MySQL 存在不同。
以下为 TiDB 事务恢复的过程(未找到相关资料,仅供参考)
- 由于 TiDB 是无状态机制,所以在整个系统宕机之后,重启 TiDB 即可。
- 恢复数据(通常是未落盘的内存数据),由于 TiDB 的数据读写都是转发到 TiKV 存储层,所以只需恢复 TiKV 数据即可,TiKV 底层是使用基于 LSM-Tree 存储结构的 RocksDB,RocksDB 写数据之前会先写 WAL 日志,所以根据 WAL 可以恢复出 L0 层(内存数据),又因为 RocksDB 是异地更新,所以不需要 redo log 将数据进行修改,这点和 MySQL 不一样,至此 TiKV 节点的数据已经恢复。
- 恢复数据后,需要根据宕机前事务的状态恢复事务状态,由上文可知,TiDB是采取 Percolator 的分布式事务协议,主要分为两个过程,Prepare 和Commit 两个过程中,每个步骤过程都会有持久化操作(选择主键,加锁),事务提交的成功标志为主键的锁是否被解除。所以恢复过程中,可以根据此标志判断事务是否已经提交,如果提交则按照 Percolator 协议异步提交其他同一事务的其他数据(secondaries),如果此主键还存在锁则说明事务未提交,则需要回滚数据,并删除所有的锁。至此事务完成恢复。
TiSpark
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。它借助 Spark 平台,同时结合 TiKV 以及 TiFlash 分布式行列混合集群的优势,和 TiDB 一起为用户一站式解决 HTAP (Hybrid Transactional/Analytical Processing) 的需求。
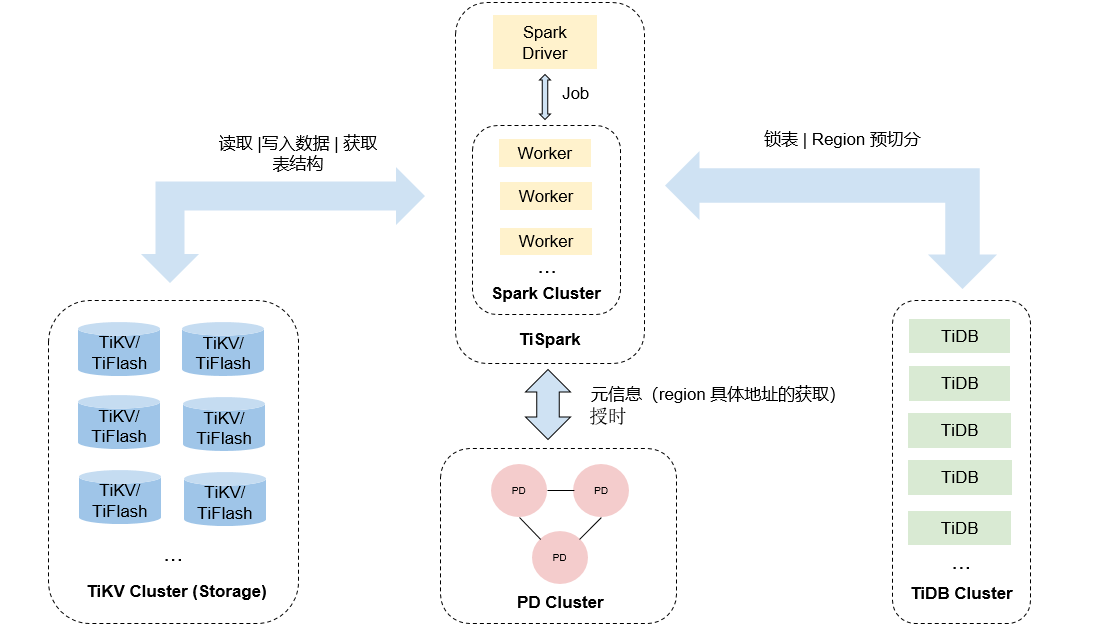
上图为 TiSpark 的结构,TiSpark 是将 Spark SQL 直接运行在分布式存储引擎 TiKV 上的 OLAP 解决方案。
TiSpark 的底层存储使用的是 基于列存的 TiFlash,相比于行存,TiFlash 根据强 Schema 按列式存储结构化数据,借助 ClickHouse 的向量化计算引擎,带来读取和计算双重性能优势。
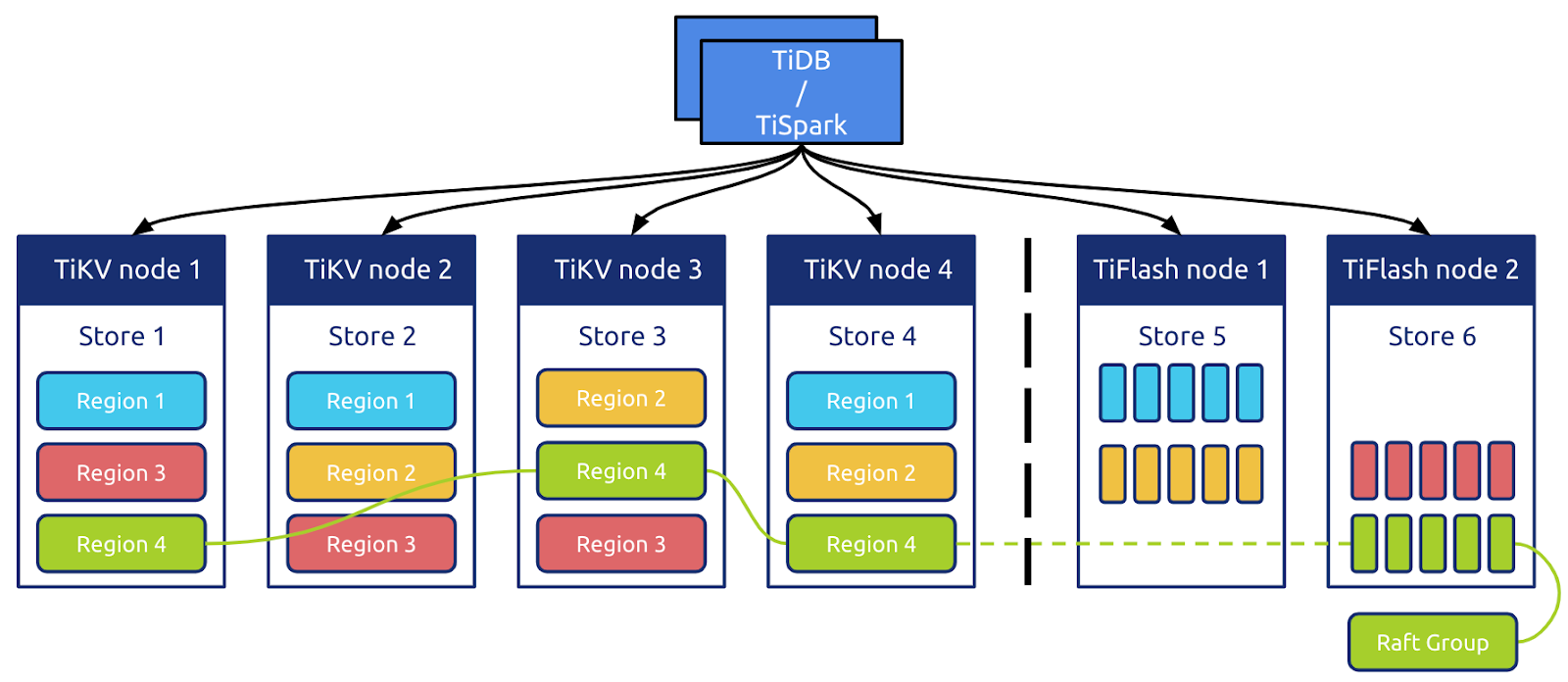
如上图所示,TiFlash 能以 Raft Learner Store 的角色无缝接入 TiKV 的分布式存储体系。由于 TiKV 本身没有 Table 的概念,TiDB 需要将 Table 数据按照 Schema 编码为 Key-Value 的形式后写入相应 Region,通过 Multi-Raft 协议同步到 TiFlash,再由 TiFlash 根据 Schema 进行解码拆列和持久化等操作。
参考文献
[1] 《TiDB 简介》. https://docs.pingcap.com/zh/tidb/stable/quick-start-with-tidb/ (见于 4月 16, 2021).
[2] 《TiDB 整体架构》. https://docs.pingcap.com/zh/tidb/stable/tidb-architecture (见于 4月 16, 2021).
[3] D. Ongaro和J. Ousterhout, 《In Search of an Understandable Consensus Algorithm》, 页 18.
[4] 《Architecture》. https://tikv.org/docs/3.0/concepts/architecture/ (见于 4月 16, 2021).
[5] 《TiFlash 简介》. https://docs.pingcap.com/zh/tidb/stable/tiflash-overview (见于 4月 16, 2021).
[6] 《3.1 关系模型到 Key-Value 模型的映射 · TiDB in Action》. https://book.tidb.io/session1/chapter3/tidb-kv-to-relation.html (见于 4月 16, 2021).
[7] 《RocksDB | A persistent key-value store》, RocksDB. http://rocksdb.org/ (见于 4月 16, 2021).
[8] 《聊聊partition的方式》. https://juejin.cn/post/6844903505975574535 (见于 4月 16, 2021).
[9] 《Multiversion concurrency control》, Wikipedia. 4月 11, 2021, 见于: 4月 16, 2021. [在线]. 载于: https://en.wikipedia.org/w/index.php?title=Multiversion_concurrency_control&oldid=1017230152.
[10] 《MVCC in TiKV》. https://en.pingcap.com/blog/2016-11-17-mvcc-in-tikv (见于 4月 16, 2021).
[11] 《Isolation (database systems)》, Wikipedia. 3月 02, 2021, 见于: 4月 16, 2021. [在线]. 载于: https://en.wikipedia.org/w/index.php?title=Isolation_(database_systems)&oldid=1009840377.
[12] H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O’Neil和P. O’Neil, 《A Critique of ANSI SQL Isolation Levels》, 页 13, 1995.
[13] D. Peng和F. Dabek, 《Large-scale Incremental Processing Using Distributed Transactions and Notifications》, 2010.
[14] 《Database · 原理介绍 · Google Percolator 分布式事务实现原理解读》. http://mysql.taobao.org/monthly/2018/11/02/ (见于 4月 16, 2021).
[15] 《Percolator 和 TiDB 事务算法 | PingCAP》, MySQL at Scale. No more manual sharding. https://pingcap.com/blog-cn/percolator-and-txn/ (见于 4月 16, 2021).
[16] 《TiDB 新特性漫谈:悲观事务 | PingCAP》. https://pingcap.com/blog-cn/pessimistic-transaction-the-new-features-of-tidb/ (见于 4月 16, 2021).
[17] 《6.2 悲观事务 · TiDB in Action》. https://book.tidb.io/session1/chapter6/pessimistic-txn.html (见于 4月 16, 2021).
[18] 《5.3 多数副本丢失数据恢复指南 · TiDB in Action》. https://book.tidb.io/session3/chapter5/recover-quorum.html (见于 4月 16, 2021).
[19] 《TiSpark User Guide》. https://docs.pingcap.com/tidb/stable/tispark-overview (见于 4月 16, 2021).
[20] 《TiFlash 简介》. https://docs.pingcap.com/zh/tidb/stable/tiflash-overview (见于 4月 16, 2021).
Author: DongSheng
Link: http://ehds.github.io/2021/04/17/tidb-mini-survey/
License: 知识共享署名-非商业性使用 4.0 国际许可协议